Every part of this post is over-simplified. History is messy and difficult to sum up. The original version was twice as long and still over-simplified. Just go with it.
{kind=link}
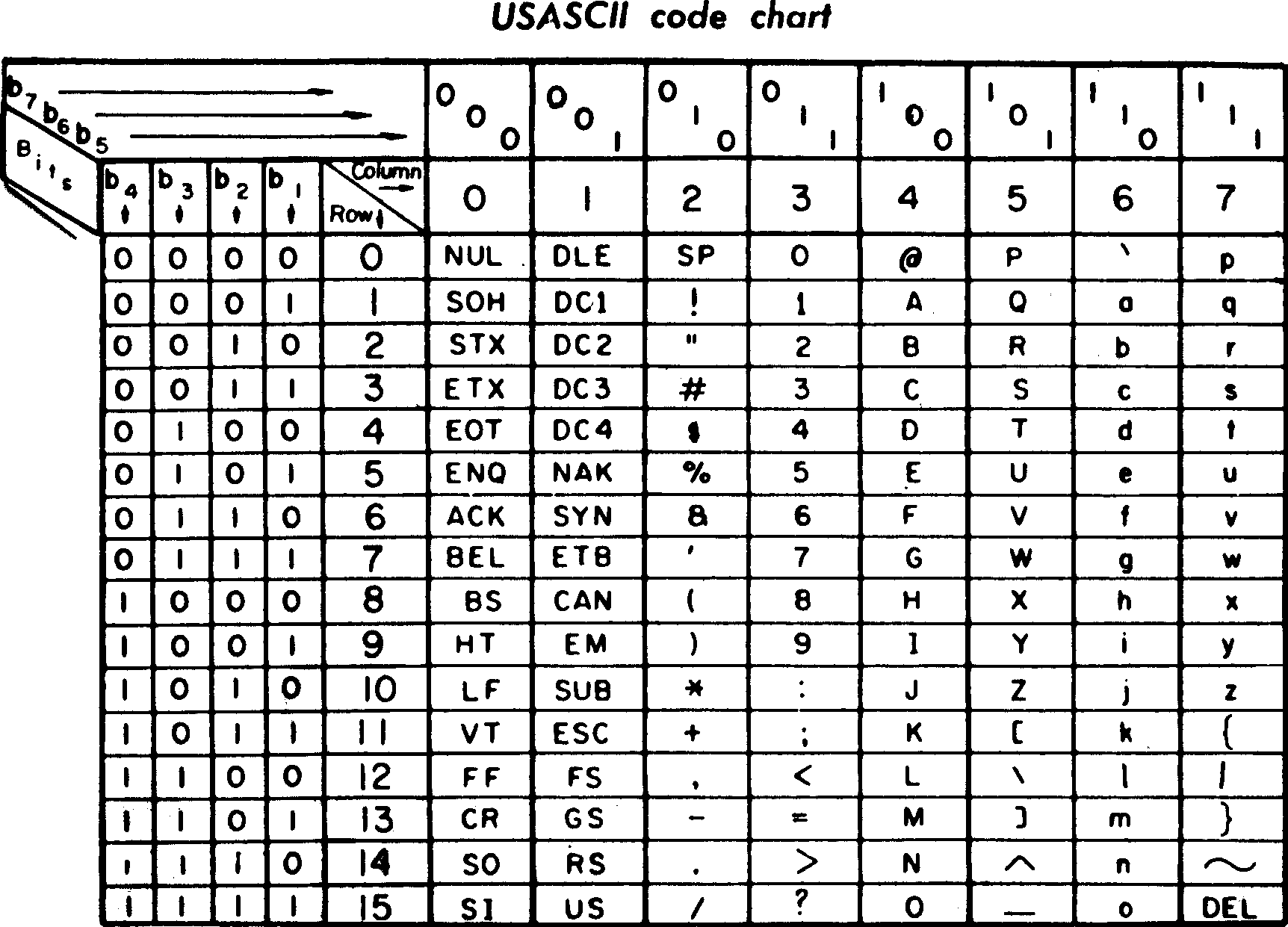
In 1961 the American Standards Association began developing a new character encoding to replace the dozens of existing systems. In the end they created the 7-bit system that we call the American Standard Code for Information Interchange. We take ASCII for granted today, almost obvious, but it’s actually very carefully designed and surprisingly clever. ASCII is inspired by automated telegraph codes that evolved to drive teletypes.
To simplify hardware implementations, ASCII splits the characters into 8 vertical “sticks,” or columns, based on the first three bits of its encoding. The first two sticks are control characters which are intended to interact with the teletype itself. Things like starting a record or moving the carriage head. And that means, in hardware, you can look at just those first two bits and decide where to route the rest of the information for decoding. Very fast. Very easy to implement.
In stick 3 (0x30-0x3F) come the digits zero through nine. That means you can just stick a “3” on the front of any digit and you get the character for that digit. That’s not an accident. Notice how uppercase and lowercase letters differ by just one bit. Makes case-insensitive search really easy, just clear one bit. Also not an accident.
Before ASCII: (E)BCDIC
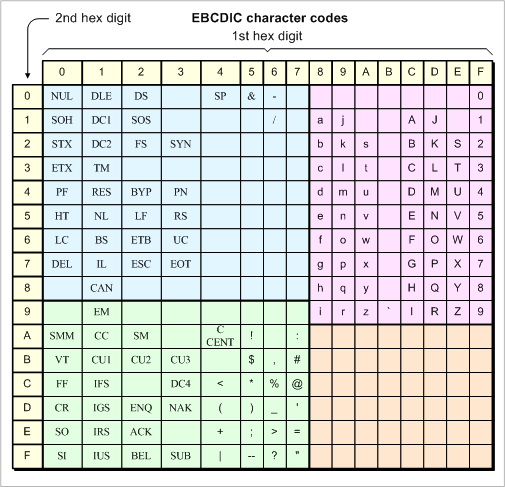
IBM, who didn’t invent ASCII but was part of the committee, had decades of experience evolving what eventually became their 8-bit EBCDIC, Extended Binary Coded Decimal Interchange Code. In EBCDIC, the decimal digits start at 0xF0 rather than 0x30, but the concept is the same.

{kind=link}
As the name suggests, it extends the previous 6-bit BCDIC format, which was designed to work with punch card equipment and mechanical tabulators, which is why it has what seem like odd “gaps” in its layout. This approach made it more compatible with the existing 6-bit systems and the related equipment. It isn’t particularly well-suited to electrical or magnetic encoding, but it taught IBM the value of lining up digits this way for BCD conversions.1
If you’re working on business-focused computers, rather than scientific computing, the math generally isn’t very complicated. There aren’t a lot of square roots or logarithms in accounting. You mostly need add, subtract, multiply, and the occasional divide. But you spend a lot of time inputting and outputting numeric results in base 10. So it makes sense to do all your math in decimal so that converting back and forth between digits and their characters is really cheap and you avoid base-conversion rounding errors. And that’s exactly what they did. A lot of IBM computers did all their math in binary coded decimal, and (E)BCDIC and ASCII reflect that.
Math!
Now at the same time, there were completely different computers being built for scientific and engineering computing. While a lot of business computers used 6-, 8-, or 9-bit characters, or “bytes,” scientific computers often worked with 36-bit “words.” They did their math in binary because it’s more efficient. It made it more expensive to convert between numbers and characters for I/O, but scientific computers do a lot more computing than they do I/O-ing.
Sidebar: It’s always the System/360 or the PDP-11
Wait, why 36 bits? Who does that? Well, 36 binary digits gives the same accuracy as 10 decimal digits.
OK, why 10 decimal digits? To match the accuracy of the mechanical calculators they competed against.
Notice the lack of powers of 2? Yeah, our obsession with powers of 2 came later.
And by “later,” I mean 1964 and the IBM System/360.

So many things about modern computers can be traced to the System/360, but one of the most ubiquitous is it used 8-bit characters, and IBM was powerful enough to make that the norm that we use to this day. Before the System/360, “bytes” came in a variety of sizes. After the System/360, a byte was 8 bits.
Despite IBM being a massive supporter of ASCII, the System/360 used EBCDIC because it was more compatible with existing IBM peripherals. So it’s kind of a distraction on our discussion of ASCII, but it’ll come back up later. History isn’t always a simple matter of “this caused that.” Sometimes a lot of things are going on at the same time. EBCDIC technically post-dates ASCII by a few months. Sometimes history doesn’t quite follow the narrative.
The many *SCIIs
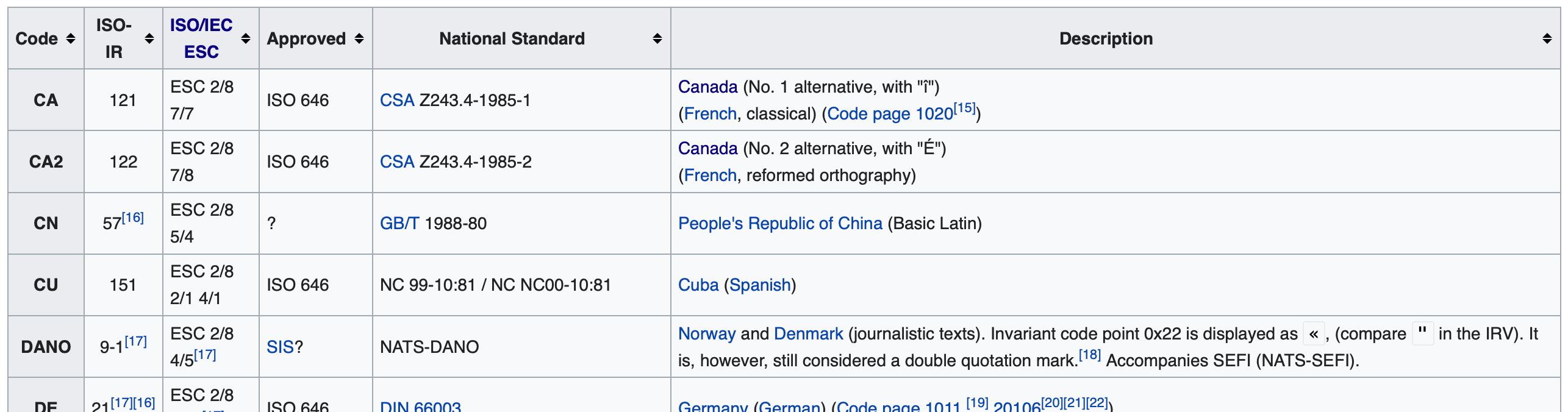
Getting back to 7-bit ASCII. ASCII was pretty clever, but it’s also very US-centric. That wasn’t because no one was thinking about other countries and cultures. ASCII is the American Standard Code. It is just one of numerous national standards under the ISO/IEC 646 umbrella. For example, there’s YUSCII, the Yugoslav Standard Code. There’s a Chinese national standard, an Icelandic standard, two Japanese, a couple of Canadian. There’s a ton of them.
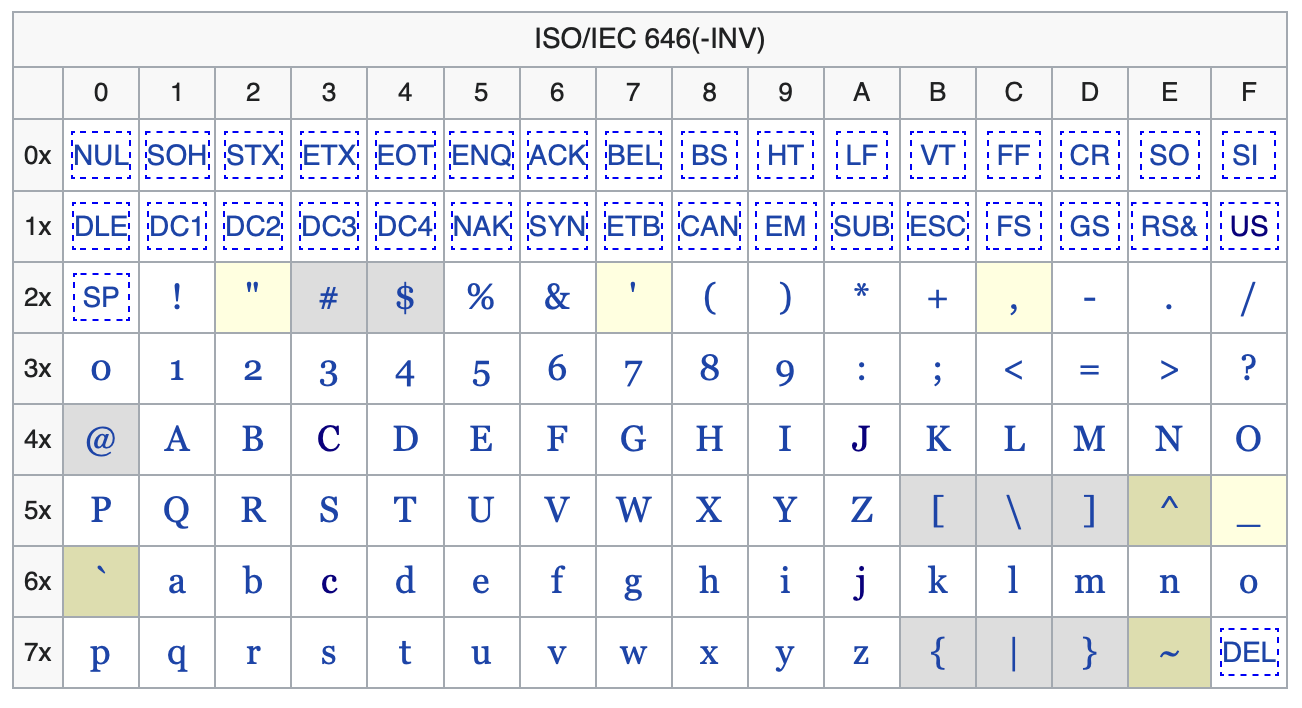
The idea was that there were certain invariant characters across standards, the ones in white, and then countries could assign whatever they wanted to certain code points, the ones in gray. And they could get combining characters using a backspace with diacritics. But you’ll notice there are only 9 customizable characters. Not a lot to work with. And building accented characters with backspace makes many text algorithms very hard.
But after the System/360 (I told you it’d come back up), more computers moved to 8-bit characters. And with the rise of microcomputers, most of which were 8-bit, there was this extra bit to work with. Some systems used the extra bit to carry extra information, or used it as a parity bit to detect data corruption. But it could also be used to get another 128 characters. That’s a lot, but it’s still nowhere close to enough to cover everything you’d want, even just for Latin-based writing systems.
So all those ISO/IEC 646 national standards morphed into a menagerie of ISO/IEC 8859 “extended ASCII” encodings, establishing the American national standard as the base that others built on, and thankfully getting rid of the “backspace for diacritics” system. The most popular was Latin-1, based mostly on an older DEC standard called the Multinational Character Set. It does a pretty good job of covering Western European languages, along with several others.
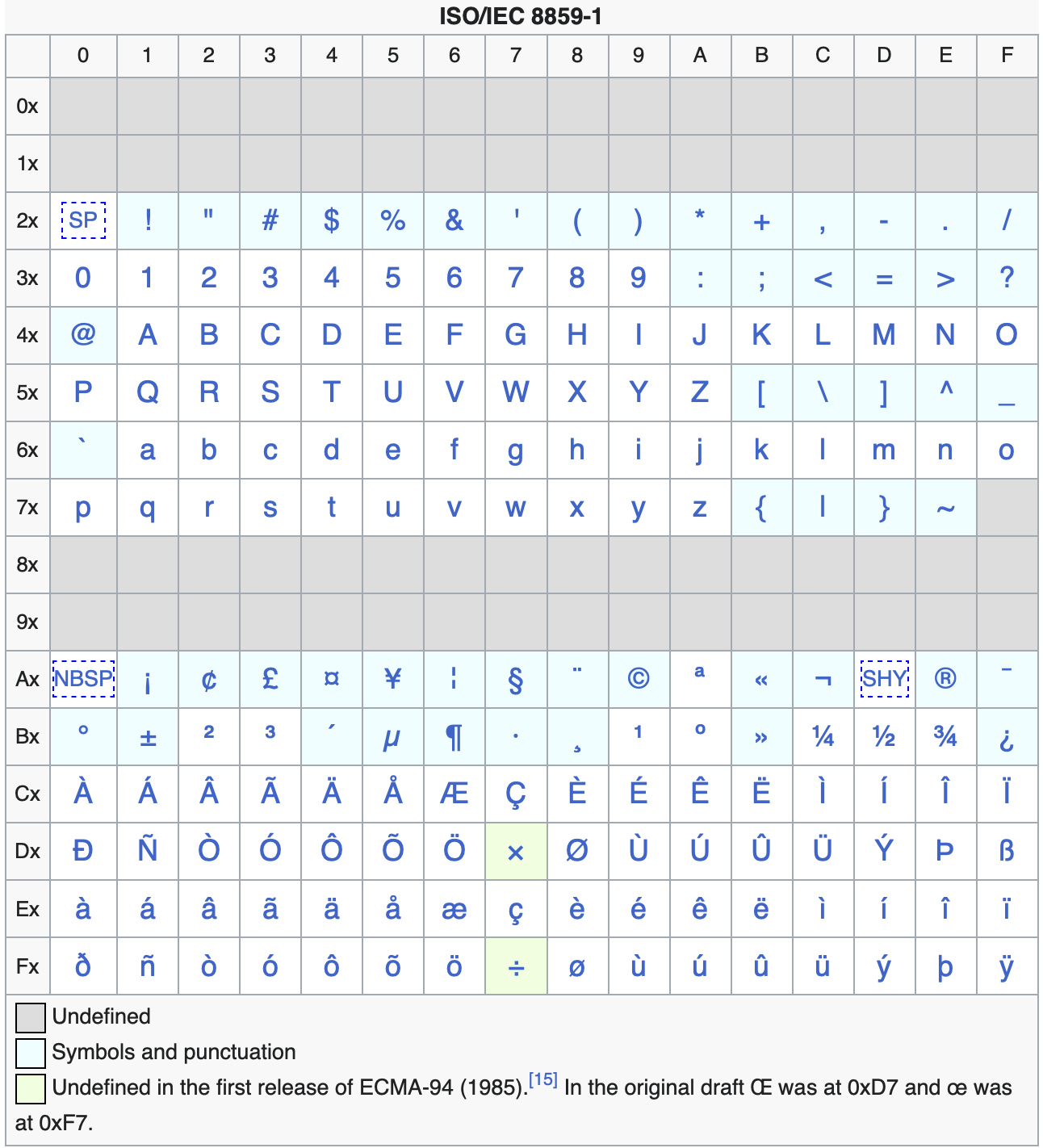
But on the other hand, consider:
- Język Polski (Polish)
- Latviešu Valoda (Latvian)
- Hànyǔ Pīnyīn (Chinese Pinyin)
They’re all “Latin-based,” but they all need characters, mostly in the form of diacritics or tone marks, that aren’t in Latin-1. And if you like diacritics and tone marks on your Latin, you can have that, too:
- Tiếng Việt (Vietnamese)
Oh dear….
So Latin-1 only does a “pretty good job” for Western European languages, but there are still a lot more languages out there using Latin that need their own extended ASCII. Non-Latin alphabets like Cyrillic, Greek, Arabic, Hebrew, and Thai are all encoded using different forms of extended ASCII, too. Even Asian-language encodings like Big5 and Shift JIS are based on ASCII, or at least compatible with it. The number 65 is the encoding of the uppercase Latin A almost everywhere, even in non-Latin encodings. Not an accident.
But this consistency can also be a problem. The encodings are “almost compatible.” They’re so compatible that it is very difficult to look at an arbitrary text file and determine what encoding it’s in. Extended ASCII is also very “dense.” Every possible sequence of bytes is a valid extended ASCII string. If you encounter the string “Tiêìng Viêòt”, have you accidentally treated the CP1258 encoding of “Tiếng Việt” as if it were Latin-1? Or is this text intentional, like it is in this document?
Even worse, there’s no easy way to mix encodings in the same document. Even if you add markup to indicate the encoding of each section, algorithms like searching becomes incredibly hard. And if you jump into the middle of a document, or worse, a stream, you have to rewind to find out what the current encoding is.
It’s…bad.
What if we “unified” all of this? 🤔
It took a few decades to finally build a better way. But that’s for another post.
-
I’m familiar with the common story that says that EBCDIC is laid out the way it is to minimize sequential holes in order to prevent weakening the card. I can’t find any primary source for that, and it doesn’t really follow from the character layout. The only evidence I’ve seen given is the slightly surprising placement of the ‘S’ encoding. But I expect that this was more about placing the ‘/’ encoding near the numbers in the older 6-bit encodings (the ones where the letters are “backwards”). Just modifying the ‘S’ encoding slightly shouldn’t have much if any impact on tape or card integrity. If the goal were to manage where holes show up, I would expect the letters to be laid out based on some English-frequency basis, or scattered around the encoding table, not laid out compactly and alphabetically. I’ve been reading Coded Character Sets, History and Development, published in 1980, and I can’t find any mention of BCD encodings trying to optimize hole placement. ↩